
W mojej pracy zdarzyło się, że musiałem polskich liter pozbawić nazwy produktów w sklepie internetowych by podstawić je do linków tworzonych przez system zarządzania sklepem.
Potrzebowałem tego również by na podstawie imion i nazwisk wygenerować adresy email.
Zobacz plik roboczy.
Usuwanie polskich znaków bez zważania na wielkość liter
W obu powyższych zastosowaniach mogłem zignorować kwestię wielkości liter. Zarówno linki jak i maile nie biorą ich pod uwagę. Użyłem następującej formuły.
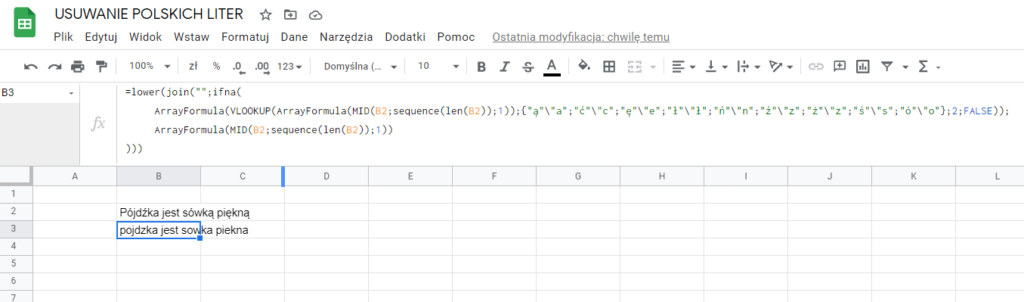
=lower(join("";ifna(
ArrayFormula(VLOOKUP(ArrayFormula(mid(B2;sequence(len(B2));1));{"ą"\"a";"ć"\"c";"ę"\"e";"ł"\"l";"ń"\"n";"ź"\"z";"ż"\"z";"ś"\"s";"ó"\"o"};2;FALSE));
ArrayFormula(mid(B2;sequence(len(B2));1))
)))
Rozbierzmy tą formułę by zrozumieć o co chodzi.
Najbardziej wewnętrzna (a więc uruchomiana jako pierwsza) jest sekwencja:
ArrayFormula(mid(B2;sequence(len(B2));1)) – bierze ona po kolei wszystkie znaki w badanym ciągu (B2). Formuła mid bierze z komórki najpierw znak pierwszy, potem drugi, trzeci, etc. Tą kolejność wyznacza jej funkcja zapętlająca sequence przyjmująca wartości od 1 do wartości odpowiadającej długości ciągu w B2, czyli len(B2). Poprzez zastosowanie arrayformula możemy wykonać operację wiele razy.
Jeśli puścimy ją samodzielnie, jej efekt będzie następujący – powstanie tabela:
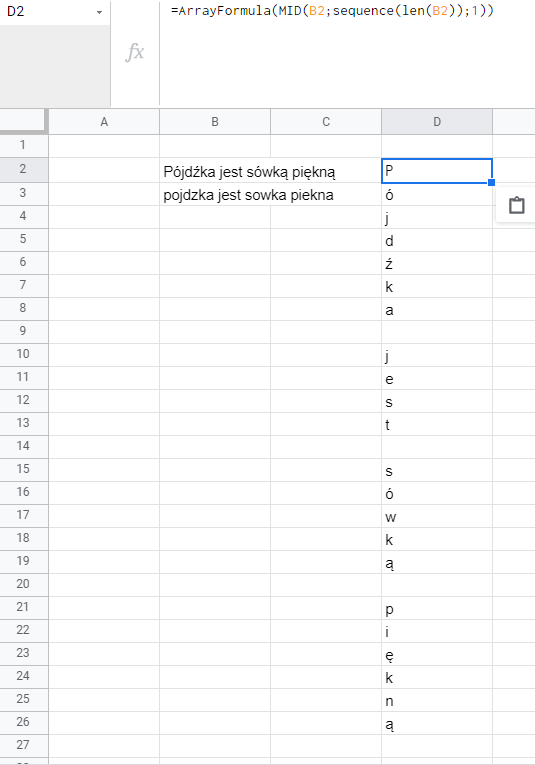
Skoro mamy tabelę, to możemy przy pomocy formuły vlookup przejść po niej i przypisać każdej polskiej literze jej odpowiednik bez ogonka. Żeby nie zajmować miejsca w komórkach, tablica przypisań jest umieszczona w samej formule.
ArrayFormula(VLOOKUP(ArrayFormula(MID(B2;sequence(len(B2));1));{"ą"\"a";"ć"\"c";"ę"\"e";"ł"\"l";"ń"\"n";"ź"\"z";"ż"\"z";"ś"\"s";"ó"\"o"};2;FALSE))
To co widzimy w nawiasie klamrowym jest odpowiednikiem tabeli wyglądającej tak:

Przesukujemy tabelę stworzoną z rozebranego zdania i za każdym razem, gdy znajdziemy polską literę to podstawiamy wartość z drugiej kolumny stworzonej tabeli przypisań.
Jeśli nie będzie polskiej litery, wyskoczy błąd N/A, wówczas zostanie przepisana litera taka jaka była. Do tego jest wykorzystywana formuła IFNA – za każdym razem kiedy jest błąd, jest uruchamiana formuła: ArrayFormula(mid(B2;sequence(len(B2));1)) , która wpisuje aktualnie badany znak.
Na koniec używam funkcji join by złożyć tabelę w jedną komórkę, oraz lower, która zamienia wszystkie wielkie litery na małe.
Dlaczego nie rozróżnia wielkości liter?
Wynika to z cech formuły vlookup, która nie jest wrażliwa na wielkość liter. Dla niej Ą i ą są identyczne.
Usuwanie polskich znaków z zachowaniem wielkości liter
Nowa formuła jest bardzo podobna, natomiast zamiast znaków porównujemy ich numery w tablicy Unicode (to tabela w której każdemu znakowi jest przypisany numer. Zawiera zarówno małe, wielkie litery, wszelkie “ogonki”, a także znaki specjalne i pokaźny zbiór emotikonów).
Literze Ą odpowiada numer 260, a ą 261. Tworzymy więc tablicę, w której określimy jakim kodom mają odpowiadać litery “bez ogonków”. W standardowym zapisie wygląda ona tak:
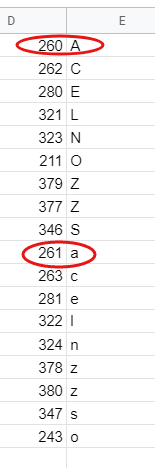
Gotowa formuła wygląda tak:
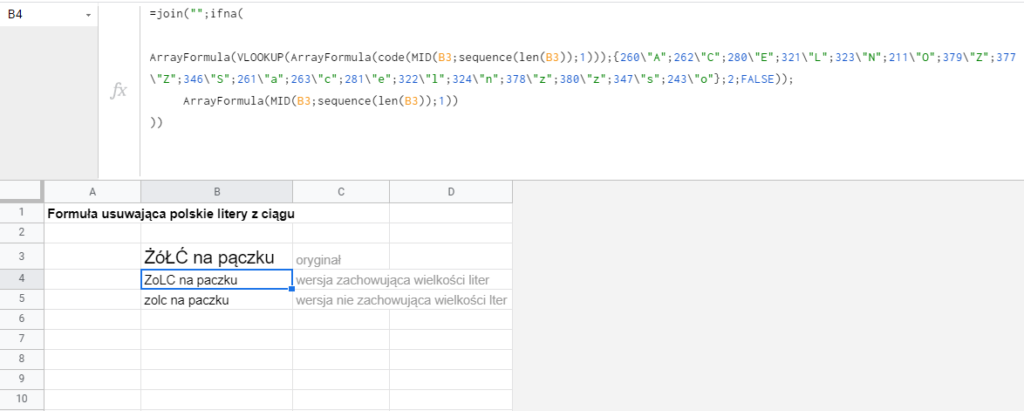
=join("";ifna(
ArrayFormula(VLOOKUP(ArrayFormula(code(MID(B3;sequence(len(B3));1)));{260\"A";262\"C";280\"E";321\"L";323\"N";211\"O";379\"Z";377\"Z";346\"S";261\"a";263\"c";281\"e";322\"l";324\"n";378\"z";380\"z";347\"s";243\"o"};2;FALSE));
ArrayFormula(MID(B3;sequence(len(B3));1))
))
W porównaniu z poprzednią jest dodana formuła code(), która zamienia znaki na kody Unicode, oraz tabela.
Działa to tak:
Jak podmieniać inne znaki?
W przypadku konstruowania linków, może być konieczne zamienianie spacji na myślniki lub podkreślenia. Mogą się też trafić inne znaki diakrytyczne. W tej sytuacji należy poszerzyć tablicę używając znaku \ by rozdzielać znaki w jednej kolumnie i ; by przechodzić do kolejnego wiersza. Jeśli chcemy poznać kod odpowiadający znakowi, wystarczy że wpiszemy =code("tu znak") i arkusz wyświetli odpowiedni kod.
 Jak zamienić DUŻE LITERY na małe, odwrotnie i jak zaczynać z wielkiej litery
Jak zamienić DUŻE LITERY na małe, odwrotnie i jak zaczynać z wielkiej litery Vlookup ( Wyszukaj.pionowo ) – czyli gdybym miał wybrać jedną najważniejszą funkcję…
Vlookup ( Wyszukaj.pionowo ) – czyli gdybym miał wybrać jedną najważniejszą funkcję… Jak okiełznać kolory w arkuszach?
Jak okiełznać kolory w arkuszach? Jak oczyścić zdobyte dane. Jak zmienić format na liczbowy, usunąć nazwy walut i inne śmieci.
Jak oczyścić zdobyte dane. Jak zmienić format na liczbowy, usunąć nazwy walut i inne śmieci.