
Zdarza się, że tworząc jakąś bazę, musimy wypełnić ją losowymi danymi, żeby sprawdzić czy działa. Najczęściej wklepujemy wówczas coś z głowy. Ewentualnie kopiujemy jakieś prawdziwe dane. Jednak nie zawsze mamy je pod ręką, nie zawsze jest to legalne (bo dane są poufne lub naruszają RODO). Żeby pomóc w takich zadaniach zbudowałem generator imion i nazwisk. Używa on publicznych danych ze strony dane.gov.pl – z ogólnopolskiej bazy PESEL. Zatem mamy do czynienia z prawdziwymi statystykami. I postaramy się stworzyć bazę w której będą występować zarówno najpopularniejsze imiona i nazwiska jak i te rzadsze. Zatem będziemy mieli często Nowaków i Kwiatkowskich, Janów i Krzysztofów, ale co jakiś czas (jak to w życiu) trafi się też jakiś oryginał jak Zenobiusz Ukleja (Zenobiuszów jest w Polsce 1512, a mężczyzn o nazwisku Ukleja 785). A to wszystko za pomocą kilku funkcji Arkuszy Google.
Zaczynam od ściągnięcia plików z bazy PESEL i wklejenia ich do mojego roboczego arkusza.
Tu jest gotowy generator (kliknięcie w ikonę spowoduje zrobienie nowej kopii dla Ciebie: )

Baza danych imion i nazwisk wraz z popularnością
Baza danych PESEL jest darmowa, w pełni legalna i udostępniana przez adminstrację państwową. Nie ma więc mowy o żadnym ryzyku użycia danych. Zwłaszcza, że tworzymy fikcyjne imiona i nazwiska.
Zauważyłem, że najpopularniejsze generatory zawierają błędy i nie bardzo radzą sobie z kwestią popularności. Ten, który wyświetla się jako pierwszy w wynikach google. miesza płcie i zdecydowanie za często wrzuca nietypowe imiona.
Ja sięgnąłem wprost do surowych danych.
Linki do źródeł danych:
Na szczęście pliki są czytelnie sformatowane. Są niestety bardzo duże. Część w formacie .xlsx (Excel), a część .csv (surowe dane). Nie będę szczegółowo opisywał procesu importu (Generalnie Plik —> Importuj). Jest on dość prosty, wymaga tylko nieco porządkowania.
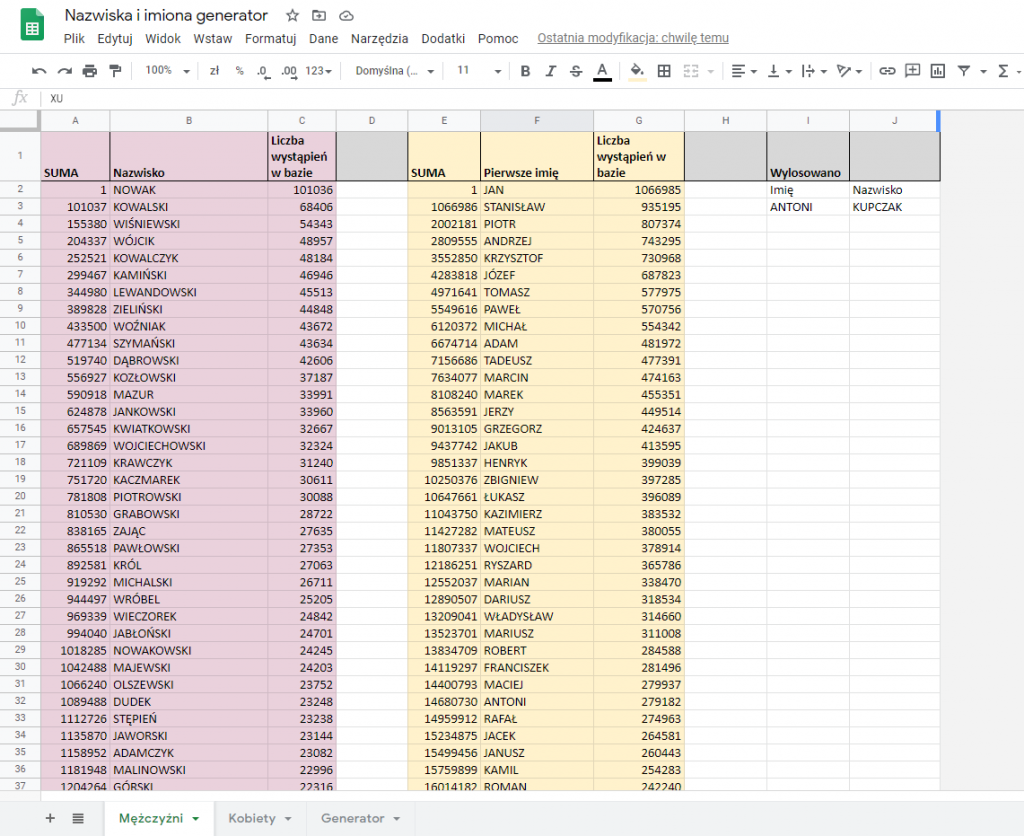
Po wgraniu zakładka z męskimi nazwiskami wygląda tak:
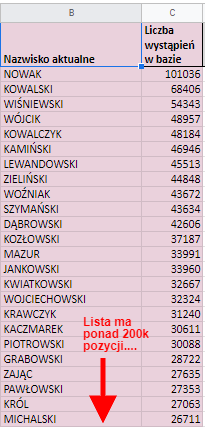
Lista nazwisk wraz z ilością ich wystąpień posłuży mi do wiarygodnego generowania. Chcemy, żeby Nowak był na tej liście odpowiednio często. Wedle statystyki powinien wyskakiwać średnio raz na 200 nazwisk.
Radzę sobie z tym tworząc nową kolumnę w której kumuluję wystąpienia wszystkich nazwisk. “Obywatel” od 1 do 101036 będzie Nowakiem, od 101037 do 155379 Kowalskim itd. Listę zamyka nazwisko ŽYBORT które nosi w Polsce dwóch obywateli.
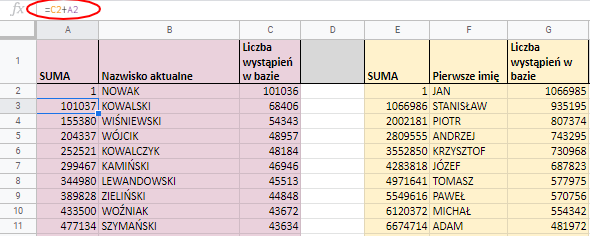
Będę za moment losował i odczytywał wartości z kolumny z nazwiskami. Nowaka wylosuję jeśli padnie liczba od 1 do 101036 natomiast 19810639 lub 19810640 to będzie ŽYBORT.
Losowanie pojedynczego nazwiska
Do losowania używam połączenia kilku funkcji:
RANDBETWEEN pozwala mi wylosować liczbę z określonego zakresu. Tutaj chodzi mi o to by wylosować któregoś obywatela z bazy liczącej ponad 19 milionów (mężczyzn zarejestrowanych w bazie PESEL). Funkcja MAX ma mi przyspieszyć znalezienie najwyższego numeru w bazie – bez jechania na koniec arkusza. Zatem złożenie:
=randbetween(1;max(A2:A)) generuje liczbę pomiędzy 1 a 19810640 (najwyższa wartość w kolumnie A).
To wszystko opakowane jest funkcją VLOOKUP (omówioną szeroko w osobnym wpisie).
=vlookup(randbetween(1;max(A2:A));A2:C;2;true) bierze wygenerowaną liczbę, przegląda tabelę A2:C i zwraca zawartość drugiej (2) jej kolumny. Wartość true mówi, że kolumna jest posortowana. Jeśli nie zostanie znaleziona konkretna wartość, funkcja ma zwrócić wartość z najbliższego jej wiersza. (Dlatego jeśli wylosujemy liczbę 2 czy 102 to pojawi się Nowak, a nie informacja o błędzie).
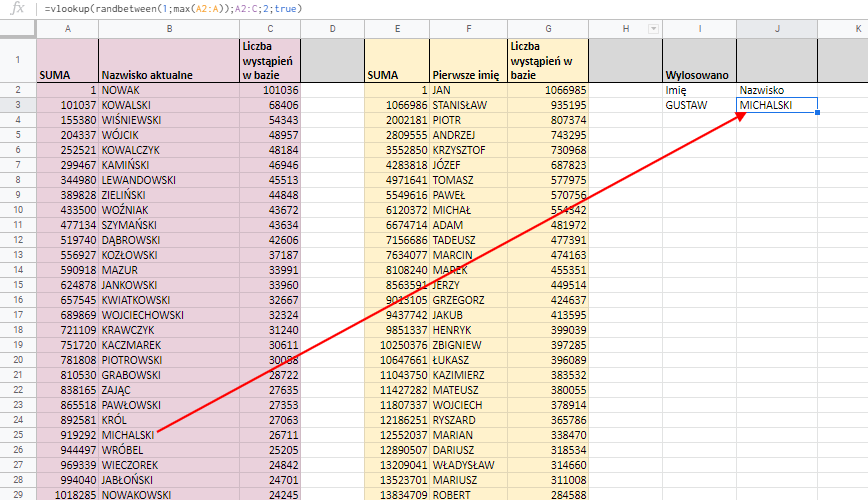
Analogicznie robimy losując z bazy imię.
Baza imion i nazwisk kobiecych.
Te bazy również pobieram z baza.gov.pl – pliki są jeszcze dłuższe niż męskie, ponieważ kobiet jest ciut więcej w kraju, a ponadto częściej zdarzają się im podwójne nazwiska. Ze względu na ograniczenia wielkości Arkuszy Google i prędkość działania, przycinam bazę do 150 tysięcy pozycji. Miłośnicy dziwnych nazwisk i tak nie poczują się oszukani. Pani Tarełko, Kokocka, Fiuta, Ciepaj się załapały. W zakładce ‘kobiety’ tworzę identyczny mechanizm losowania jak dla mężczyzn.
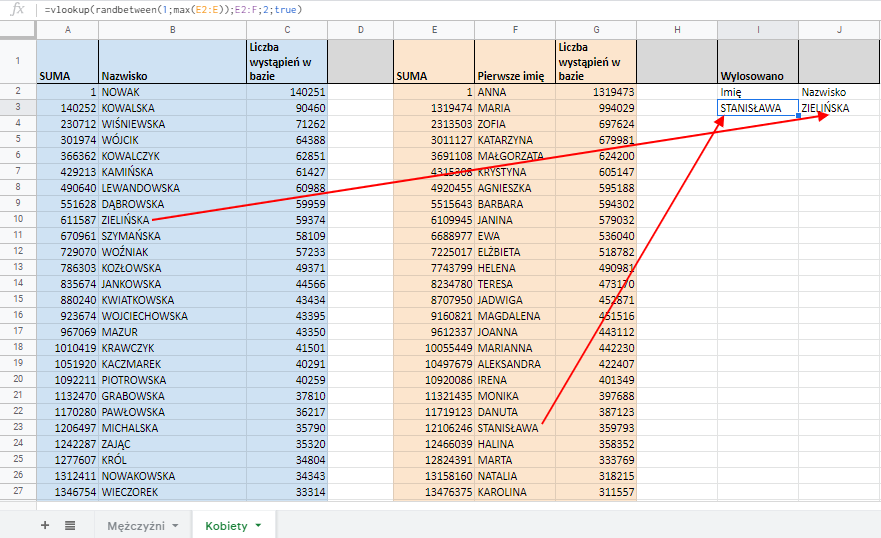
Automatyczne generowanie listy imion i nazwisk
Skoro umiemy już wygenerować pojedyncze imię i nazwisko, spróbujmy się z całą listą. Tworzę w tym celu zakładkę ‘Generator’. Naszym celem jest szybkie tworzenie listy. Wystarczy, że zadeklarujemy jej długość i udział % kobiet. Coś takiego:
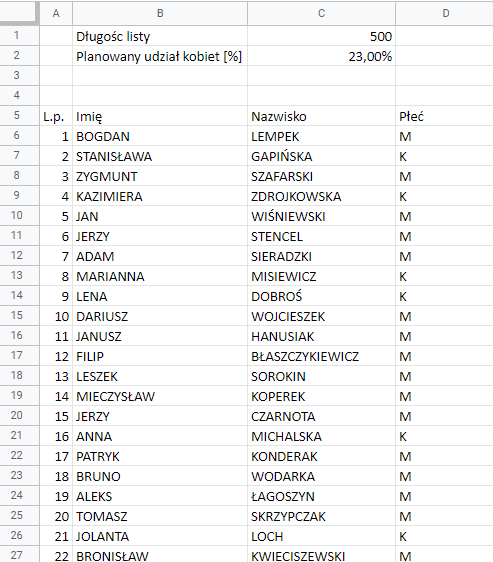
Zaczniemy od numeru początkowego. Zwykle robimy to przeciągając myszką. Ponieważ długość listy będzie się zmieniać, a nie chcemy mieć zwisających pustych numerów, będziemy kolumnę z liczbą początkową generować przy pomocy formuły SEQUENCE.
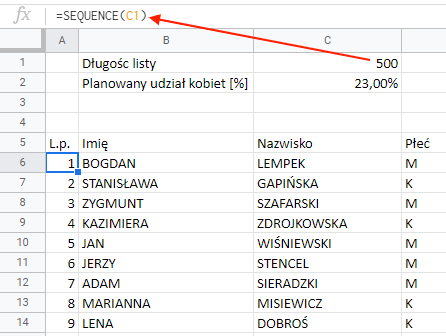
Składnia SEQUENCE:
=SEQUENCE(ilość wierszy; [ilość kolumn]; [wartość_początkowa]; [krok])
Składowe znajdujące się w kwadratowych nawiasach są opcjonalne. Jeśli wstawimy tylko jedną zmienną, jako wartość początkowa zostanie przypisana 1, a krok również 1. Mamy zatem sprawę rozwiązanę – numery pozycji skończą się wraz z resztą danych.
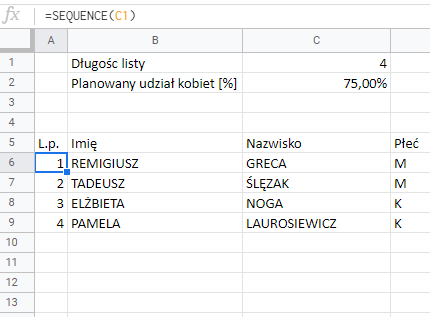
Reszta jest nieco bardziej skomplikowana. Ale tylko NIECO.
Zaczniemy od tego, że potrzebujemy osobnego losowania. Losowej wartości dla imienia, dla nazwiska i dla płci. W sumie trzech wartości dla każdej osoby. Tworzymy w tym celu tabelę liczb losowych. Służy do tego funkcja RANDARRAY.
Składnia RANDARRAY(ilość wierszy;ilość kolumn)
Funkcja RANDARRAY tworzy tabelę o wskazanej wielkości i wypełnia ją liczbami losowymi od 0 do 1.
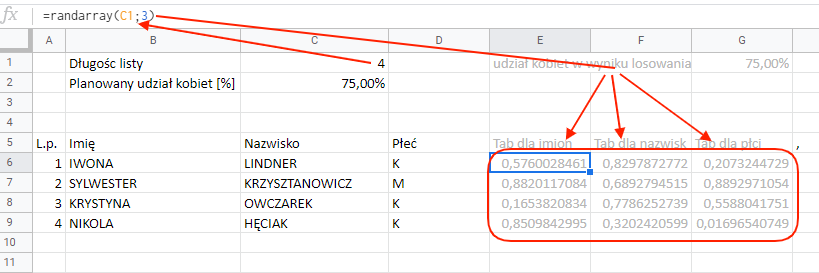
Wybieranie płci we wskazanych proporcjach
Ustaliliśmy np. że chcemy mieć 75% kobiet w zestawieniu. Żeby to osiągnąć, bierzemy kolumnę G i patrzymy czy liczby losowe są większe niż 0,75. Jeśli są – to wygenerujemy mężczyznę, jeśli mniejsze – kobietę. Dla pojedynczej linii będzie to wyglądać następująco:
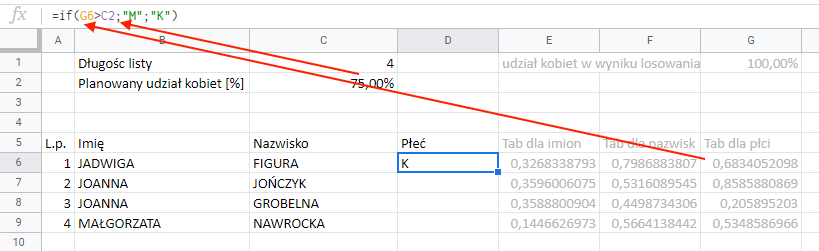
A ponieważ chcemy, żeby płeć została przypisana do całej listy, musimy stworzyć funkcję która nam wygeneruje od razu tablicę płci odpowiadającą zadanej długości. W tym celu używamy funkcji ARRAYFORMULA i ARRAY_CONSTRAIN opisanych szczegółowo w osobnym wpisie.
ARRAYFORMULA pozwala poszerzyć działanie formuł na cały zakres, natomiast ARRAY_CONTRAIN ogranicza tabelę do wskazanych wielkości.
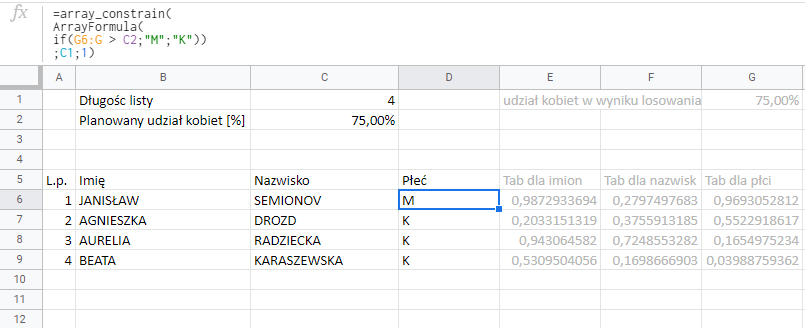
Zastosowanie funkcji ARRAYFORMULA pozwoliło poszerzyć działanie funkcji IF. Teraz nie porównuje już tylko G6 z C2 ale najchętniej by porównało wszystkie komórki z zakresu G6:G z wartością C2 i wpisało odpowiednio M lub K. Funcja ARRAY_CONSTRAIN ogranicza działanie ARRAYFORMULA – pozwala jej działać tylko w czterech wierszach (czyta to w komórce C1 i w jednej kolumnie – stąd wartość 1 na końcu).
Losowanie imion i nazwisk z bazy – dla całej tabeli
W zakładkach ‘Kobiety’ i ‘Mężczyźni’ mamy mechanizm pozwalający wylosować pojedyncze imię wraz z nazwiskiem, z uwzględnieniem popularności w bazie danych. Teraz pójdziemy o krok dalej. Przy pomocy jednego zapisu, wygenerujemy całą listę nazwisk, biorąc pod uwagę jaka ma być płeć.
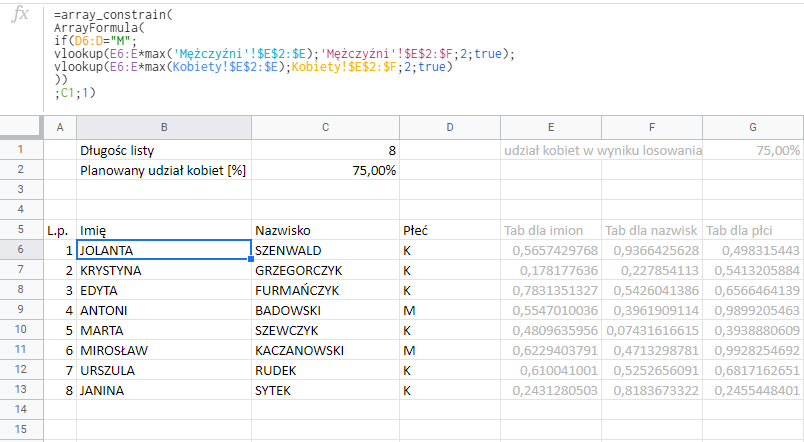
Zacznijmy od tego jak w tym wypadku pociągniemy jedno nazwisko:
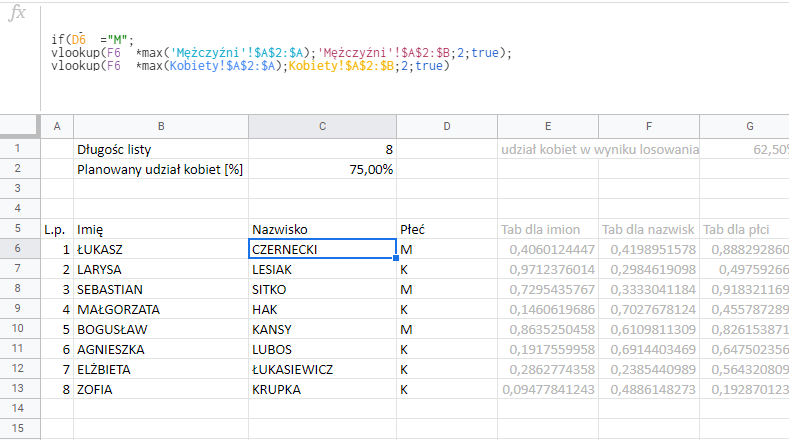
Rozbijmy ten zapis:
Jeśli (IF) w D6 jest M to wykonaj jedną funkcję VLOOKUP, a jak M tam nie ma to wykonaj drugą funkcję VLOOKUP.
W funkcji vlookup weź wartość losową z kolumny F (np. 0,419895…) i pomnóż ją przez najwyższą wartość z kolumny A w bazie nazwisk męskich (tam są skumulowane liczby od 1 do około 19 mln.). Następnie podaj wartość z 2 kolumny z bazy nazwisk (czyli samo nazwisko). Jeśli wylosowana wartość jest bliska 0, to wyświetli się popularne nazwisko jak Nowak, Kamiński czy Kwiatkowski. Jeśli natomiast wartość w kolumnie E będzie wysoka, to z bazy w zakładce ‘Mężczyźni’ zostanie pobrane rzadkie nazwisko. Jak omówiłem już wcześniej – popularne nazwiska pojawiają się odpowiednio częściej.
Po odsłonięciu funkcji ARRAYFORMULA i ARRAY_CONSTRAIN nasza formuła wygląda następująco:
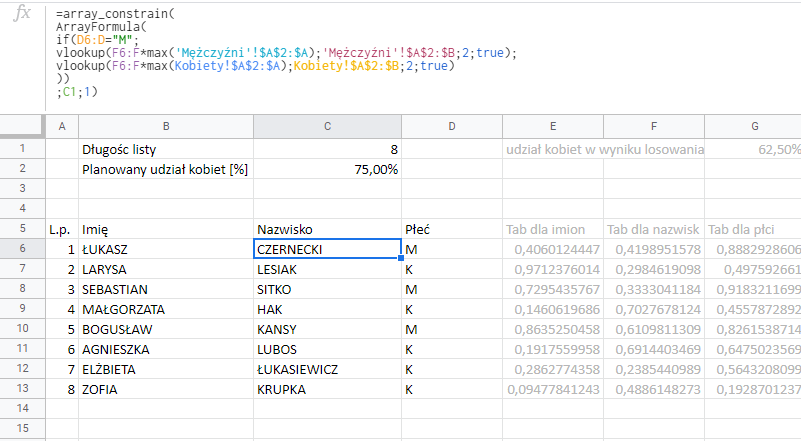
Dla imion formuła losująca wygląda analogicznie:
Zauważone ograniczenia i inne spostrzeżenia
Widać, że baza odnosi się do całej populacji i do niektórych zastosowań może dawać dziwne wyniki. Np. 198 pod względem popularności imię w Polsce to BRAJAN. Jest ich w kraju 5581. Nie sądzę by ktoś uwierzył w rzetelność listy, gdyby zobaczył Brajanka na liście np. kombatantów.
Podobnie jest w drugą stronę – Tadeuszów nie spotykamy raczej w młodym pokoleniu, tymczasem jest to 11 imię pod względem popularności. Mamy ich prawie pół miliona!
Jest jeszcze problem regionalizmów i imigracji. Trochę dziwnie wygląda YURII (ponad 12 tysięcy wystąpień w bazie) o nazwisku np. PIOTROWSKI (30 tys. obywateli).
Mi ten generator posłuży do tworzenia losowych danych do testowania arkuszy opracowujących wyniki sportowe. Ale samo obcowanie z bazą imion i nazwisk sprawiło mi sporo frajdy.
Jeśli chcesz pomajstrować samemu – przypominam, że tu jest plik roboczy. Po kliknięciu w link Arkusz wymusi byś zrobił sobie własną kopię, a nie majstrował w mojej (mechanizm wymuszający robienie kopii opisuję w osobnym wpisie)
 Wykres dynamiczny – czyli taki, który podmienia dane po jednym kliknięciu
Wykres dynamiczny – czyli taki, który podmienia dane po jednym kliknięciu Formuła QUERY w Arkuszach Google. Co to i dlaczego jest mocarne?
Formuła QUERY w Arkuszach Google. Co to i dlaczego jest mocarne? Jak zrobić symulację Lotto w Arkuszu Google?
Jak zrobić symulację Lotto w Arkuszu Google? Nie musisz kopiować formuł w dół, czyli ARRAYFORMULA.
Nie musisz kopiować formuł w dół, czyli ARRAYFORMULA.