
Arkusze Google zawierają kilka funkcji wykorzystujących wyrażenia regularne. I są to funkcje które możesz zagnieżdżać. Dla bezpieczeństwa aplikacji ograniczono grupę wyrażeń do tzw. RE2. Więc jeśli masz doświadczenie z wyrażeniami regularnymi i chcesz poszaleć, to ostrzegam że tylko wycinek poligonu jest dostępny do zabawy. Ale zaraz przekonacie się, że wycinek bardzo przydatnym w codziennym życiu człowieka operującego na danych.
- Kiedy najczęściej się przydają?
- Najprostsze zastosowanie: wyszukanie konkretnej frazy
- Ignorowanie wielkości liter
- Wyodrębnienie liczby (np. ceny)
- Wyodrębnienie lub sprawdzenie charakterystycznego ciągu – np. kodu pocztowego
- Znalezienie numeru (np. seryjnego) według podanego wzorca
- Znalezienie ciągu pomiędzy konkretnymi znakami (np. w nawiasach) i obejście znaków specjalnych (nawiasów, cudzysłowów itp.).
- Jak użyć kilku wyrażeń w jednej funkcji
Kiedy najczęściej się przydają?
Wyobraź sobie, że dostajesz jakąś tabelę w .pdfie. Niestety nikt nie ma pliku edytowalnego i jedyne co możesz zrobić to skopiować ją i wkleić sobie do arkusza licząc na to, że wszystko będzie w porządku. Ale okazuje się, że komórki się sklejają i dostajesz bałagan – musisz wszystko rozwikłać by móc używać. Jeśli tabela jest na 20 wierszy – zrobisz to szybko ręcznie. Ale jeśli wierszy jest 1500 – stoisz przed grubym zadaniem i dobrze byś poczytał o wyrażeniach regularnych.
Wszystkie opisane ponizej przykłady możesz znaleźć w pliku roboczym. Jeśli chcesz go edytować, zrób sobie własną kopię (Plik –> Utwórz kopię).
W tym wpisie nie opisuję samych funkcji REGEXEXTRACT (wydobywanie wyrażenia), REGEXMATCH (sprawdzanie czy wyrażenie spełnia warunek), REGEXREPLACE (zamiany wyrażenia). Skupiam się na samych wyrażeniach. Jeśli te funkcje Ci nic nie mówią, przeczytaj wpis: Indeks słów zakazanych.
Najprostsze zastosowanie: wyszukanie konkretnej frazy
Załóżmy, że masz listę produktów skopiowaną ze strony internetowej i potrzebujesz wyodrębnić te, które zawierają słowo “Adidas”, albo “Inov-8”. Bo interesują Cię tylko produkty tej firmy.
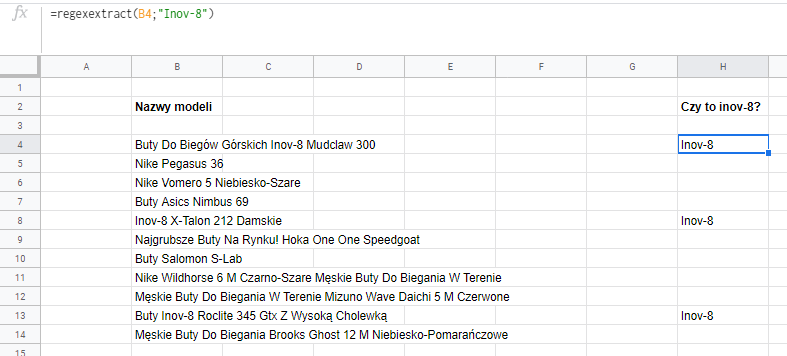
Ignorowanie wielkości liter
Standardowo wyrażenia regularne są wrażliwe na wielkość liter i jeśli wpisujemy, że poszukujemy Inov-8, to nie znajdzie nam ani inov-8, ani INOV-8, ani żadnej innej mutacji. Dlatego należy wprowadzić tzw. flagę zmieniajacą działanie funkcji. W tym wypadku będzie wyglądać tak: (?i) i umieści się ją przed wyszukiwanym wyrażeniem.
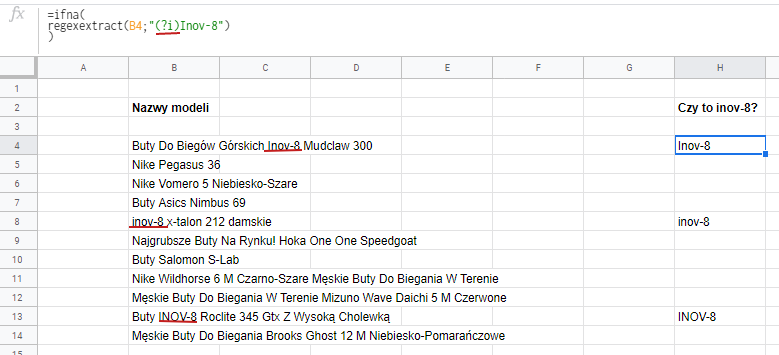
Możecie zauważyć również, że pojawiła się dodatkowa formuła ifna w którą opakowana jest formuła regexextract. Robimy to po to by uniknąć wyświetlania się błędu #N/A jeśli nie znajdziemy wartości “inov-8”.
Wyodrębnienie liczby (np. ceny)
Ten przykład pochodzi z prawdziwej rozmowy z kolegą, który miał w rękach zabałaganiony cennik akcesoriów do zegarków z GPS. Po wklejeniu do arkusza, ceny wylądowały w tych samych komórkach co nazwa produktu.
Liczby możemy opisać na 2 sposoby:
\d – odpowiada pojedynczej cyfrze
\d+ odpowiada liczbie (jedna lub więcej cyfr)
W tym przypadku widzimy, że mamy do czynienia również z liczbami w nazwie modelu. Więc nie możemy sobie zwyczajnie poprosić o podanie liczby. W dodatku mamy przecinki, które są czytane jako tekst.
To co wyróżnia wszystkie ceny to układ: cyfry (jedna do trzech), przecinek cyfry, (dwie), spacja, symbol €. Zatem poprośmy arkusz o wyodrębnienie z każdej komórki wyrażenia o takim wzorcu.
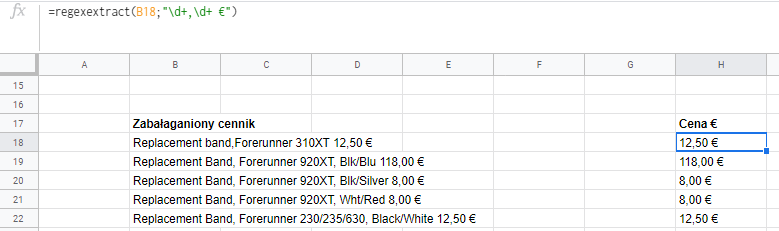
Liczby można opisywać też jako zakres znaków. Zapis [0-9] oznacza, że poszukujemy liczby od 0 do 9, natomiast [0-9]{1,3} mówi, że szukamy ciągu cyfr o długości od 1 do 3 znaków. Więc tutaj możemy zadziałać również tak:

Jak widzicie – wyodrębnione ciągi nie są traktowane jako liczby. Jak je wyczyścić by mogły być używane do działań matematycznych, możecie przeczytać w osobnym wpisie.
Wyodrębnienie lub sprawdzenie charakterystycznego ciągu – np. kodu pocztowego
Przykład bardzo podobny do poprzedniego. Wiemy, że polskie kody pocztowe mają format nn-nnn. Dwie cyfry, myślnik, trzy cyfry.
Tym razem sprawdzimy czy wszystkie wartości wpisane w bazie adresowej kodów pocztowych spełniają ten wzorzec.
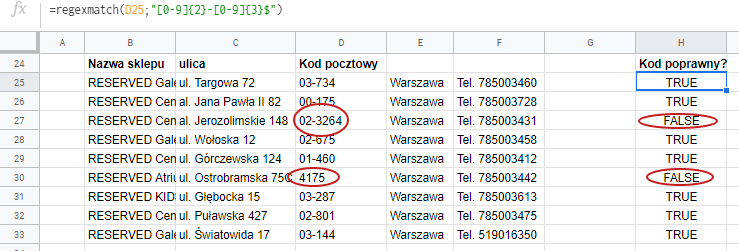
Widzimy, że funkcja regexmatch tylko daje informację czy dany ciąg spełnia wymagania. W przeciwieństwie do regexextract – nic nam nie wyciąga.
Składnia wyrażenia regularnego jest zgodna z tym co opisywaliśmy w poprzednim przykładzie. [0-9]{2} oznacza 2 cyfry, potem jest myślnik i 3 cyfry [0-9]{3}. Na końcu pojawił się dodatkowo $
$ oznacza koniec ciągu. Jeśli byśmy go nie użyli to trzeci kod z listy 02-3264 zostałby uznany za poprawny.
Jeśli chcemy poszukać ciągu na początku wyrażenia to musimy na początku podać znak ^. W sumie to wyrażenie też możemy zabezpieczyć przed wystąpieniem dodatkowych znaków i zrobić następujacy układ: =regexmatch(D25;"^[0-9]{2}-[0-9]{3}$")
Znalezienie numeru (np. seryjnego) według podanego wzorca
Weźmy tu przykład z mojej pracy. Buty marki inov-8 mają kody producenta składające się z ciągów cyfr, myślników, liczb. Ale są dość regularne.
Przykład: 000910-ORBK-P-01
- Pierwszy ciąg cyfr ma ich zawsze 6 (określa kod modelu),
- potem jest myślnik,
- później opis koloru – zawsze litery, ale to ma różną długość, bo kolorów może być więcej lub mniej.
- Znów myślnik
- Jedna litera opisująca szerokość
- Znów myślnik
- Numer wersji (dwie cyfry).
Widzimy więc, że musimy upakować kilka warunków by wyciągnąć kod z tekstu (np. wklejanego z zabałaganionego .pdfa)

Jeśli chcemy wyciągnąć nazwę podeszwy (dla przykładu to tekst X-TALON™) to też można to zrobić bardzo szybko przy pomocy funkcji REGEXEXTRACT:

- ^ – oznacza początek ciągu (czyli że przed wyszukiwaną frazą nie może nic występować,
- .+ – kropka oznacza dowolny znak, a plus że tych dowolnych znaków może być jeden lub więcej.
- ™ – oznacza znaczek trademark, który jest na końcu każdej nazwy podeszwy
Możemy też wyciągnąć nazwy kolorów, bo ta część również jest łatwa do wyodrębnienia: To zawsze są duże litery, potem / a potem znów duże litery. Więc formuła będzie wyglądać tak:

Znalezienie ciągu pomiędzy konkretnymi znakami (np. w nawiasach) i obejście znaków specjalnych (nawiasów, cudzysłowów itp.).
Zaczniemy od tekstu w którym są frazy w nawiasach. Załóżmy roboczo, że chodzi o złośliwe uwagi. Nie możemy sobie wpisać dowolnie nawiasu wewnątrz wyrażenia regularnego, bo potraktuje go jako znak grupujący wyrażenia. Więc musi być potraktowany dosłownie. W tym celu przed nawiasem stawiamy znak \

Zatem funkcja REGEXEXTRACT szuka otwarcia nawiasu, potem dowolnego ciągu znaków (jeden lub więcej) i zamknięcia nawiasu.
Możemy też usunąć te uwagi przy pomocy funkcji REGEXREPLACE.

W tym wypadku prosimy by funkcja znalazła konkretny ciąg i zamieniła go na ciąg pusty “”.
Z cudzysłowami nie jest tak łatwo się uporać, bo Arkusze traktują je jako początek i zakończenie wyrażenia regularnego. Ale możemy przenieść całe wyrażenie do osobnej komórki i odwołać się do niej:

Niewygodne znaki możemy też obchodzić opisując je przy pomocy funkcji CHAR() – zwraca ona znak o konkretnym numerze w tablicy znaków. Cudzysłów opisujemy jako CHAR(34).
W tej systuacji usunięcie ciągu znaku w cudzysłowie będzie wyglądało następująco:

Znaki & służą do łączenia kilku wyrażeń w jedno. Zatem mamy cudzysłów kolejne wyrażenie .+ (czyli dowolny ciąg znaków) i kolejny cudzysłów, a to wszystko zamieniamy na pusty ciąg: “”
Jak użyć kilku wyrażeń w jednej funkcji
Zdarza się, że spodziewamy się kilku rodzajów ciągów znaków. Wówczas w ramach jednej funkcji możemy wpisać kilka wyrażeń regularnych i funkcja zwróci nam pierwsze, które będzie spełniać kryteria. Wyrażenia rozdzielamy znakiem | który oznacza LUB.
W tym wypadku chodzi o wyodrębnienie płci z opisu butów. Wiemy, że w zabałaganionym pliku zawsze było Men’s lub Women’s. Zatem możemy wyciągnąć te ciągi, tak jak we wpisie o wykrywaczu bluzgów.

Wiem, że ten wpis nie jest kompletny i zawiera jedynie kawałek możliwości wyrażeń regularnych w arkuszach. Więcej klas wyrażeń możecie znaleźć np. tutaj
 Indeks słów zakazanych. Wykryj bluzgi w tekście. Czyli przykład zastosowania wyrażeń regularnych.
Indeks słów zakazanych. Wykryj bluzgi w tekście. Czyli przykład zastosowania wyrażeń regularnych. Jak oczyścić zdobyte dane. Jak zmienić format na liczbowy, usunąć nazwy walut i inne śmieci.
Jak oczyścić zdobyte dane. Jak zmienić format na liczbowy, usunąć nazwy walut i inne śmieci. Jak przygotować animowany wykres typu “pogoń słupków” przy pomocy Google Sheets
Jak przygotować animowany wykres typu “pogoń słupków” przy pomocy Google Sheets Jak umieścić ikony towarów z panelu Idosell w arkuszu kalkulacyjnym
Jak umieścić ikony towarów z panelu Idosell w arkuszu kalkulacyjnym