
Przykład jest nie za poważny. Ale na końcu zobaczycie, że może przydać się w pracy. Dlatego warto poczytać.
Jeśli chcecie, możecie podejrzeć wszystko w pliku roboczym. A jeśli potrzebujecie pomajstrować – wystarczy zrobić sobie kopię pliku roboczego (Menu Plik –> Utwórz kopię).
- Sporządzamy listę fraz które chcemy wykrywać
- Składamy wszystkie słowa w jeden ciąg
- Sprawdzamy czy jest fraza za pomocą funkcji REGEXMATCH (czy jest bluzg?)
- Wyciągamy poszukiwaną frazę za pomocą funkcji REGEXEXTRACT (co to za bluzg?)
- Zamieniamy frazę na coś innego przy pomocy funkcji REGEXREPLACE (może wykropkować lub wstawić @#$%!)
- Zastosowanie tej metody w pracy, czyli wykrywamy producenta w długiej nazwie
Nie rozpracowuję tu szczegółowo na czym polegają wyrażenia regularne. To sposób schematycznego zapisania tekstu. Mam zamiar poświęcić im osobny wpis. Tu używamy tylko najprostszego sposobu zapisu – sama poszukiwana fraza rozdzielana znakiem | który oznacza “lub”. Więc jeśli wpisujemy pies|kot, dostaniemy wyrażenie regularne będzie prawdziwe gdy pojawi się conajmniej jedna z fraz.
Sporządzamy listę fraz które chcemy wykrywać
Żeby wykrywać brzydkie słowa, najpierw potrzebujemy ich listy. Oczywiście w rzeczywistości jest ona dość długa i nie całkiem pokrywa się z tym co napisałem tutaj, ale można pobawić się samodzielnie, wymieniając te frazy na dowolne inne.
Zaczynamy od takiej tabeli. Naszym zadaniem jest sprawienie, że jeśli w komórce (np. w której przechowujemy komentarze użytkowników) pojawią się wymienione słowa, chcemy to wiedzieć, by móc przyjrzeć się tym komentarzom.
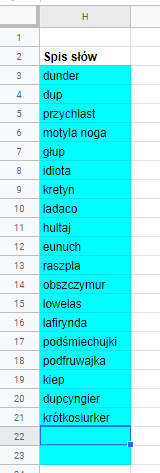
Składamy wszystkie słowa w jeden ciąg
Żeby używać tego spisu, potrzebuję go poskładać w jeden ciąg porozdzielany znakiem | . To jest mi niezbędne do robienia zapytań z wykorzystaniem wyrażeń regularnych.
Używam do tego funkcji TEXTJOIN

Szersze umówienie jej składni znajdziecie we wcześniejszym wpisie.
=textjoin("|";true;H3:H23) oznacza, że chcemy wziąć zawartość wszystkich komórek z zakresu H3:H23 i połączyć w jedną, używając separatora | i ignorując puste komórki (do tego służy słówko true).
Sprawdzamy czy jest fraza za pomocą funkcji REGEXMATCH (czy jest bluzg?)
Kiedy w komórce J3 mamy już listę, możemy testować nasze teksty.
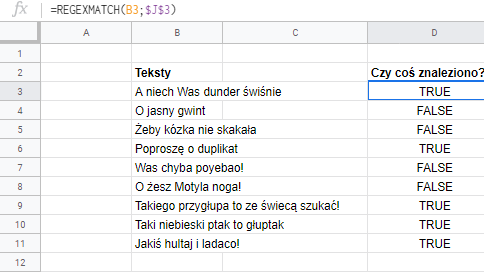
W ten sposób za pomocą funkcji REGEXMATCH określamy czy w sprawdzanych przez nas komórkach jest któraś z poszukiwanych fraz. Fraza może być częścią wyrazu i wyrażenia regularne w tym momencie są wrażliwe na wielkość liter (później opowiem jak to usprawnić).
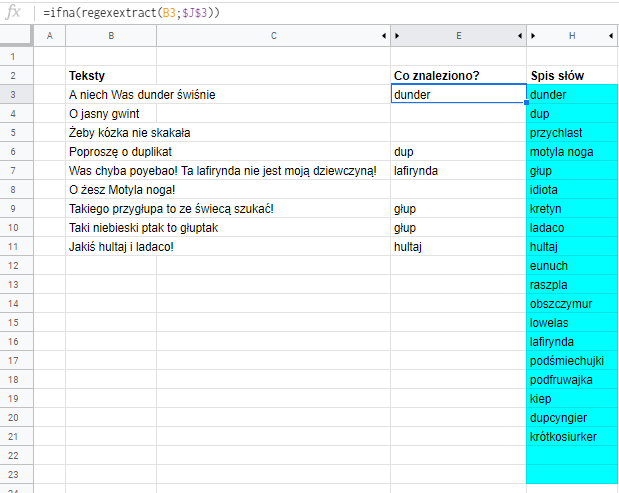
Wyciągamy poszukiwaną frazę za pomocą funkcji REGEXEXTRACT (co to za bluzg?)
Wiemy już, że jakieś frazy zostały znalezione. Jednak za pomocą pokrewnej funkcji REGEXEXTRACT możemy je wydobyć.
Składnia: REGEXEXTRACT(tekst; wyrażenie regularne)
tekst – to może być zapisany w cudzysłowie ciąg znaków lub odwołanie do komórki zawierającej tekst.
wyrażenie regularne – opis tego czego poszukujemy. W naszym przypadku spis wszystkich fraz
Wypróbowuję:
=regexextract(B3;$J$3) wyciąga z komórki B3 pierwszą napotkaną frazę znajdującą się w spisie. (który mamy w komórce J3). Ponieważ formuła jest kopiowana w dół, J3 jest adresowana bezwzględnie ($J$3), bo do niej mają się odwoływać wszystkie kopie, natomiast B3 jest adresowana względnie.
Zamieniamy frazę na coś innego przy pomocy funkcji REGEXREPLACE (może wykropkować lub wstawić @#$%!)
Ostatnia z funkcji operujących na wyrażeniach regularnych to REGEXREPLACE. Wyszukuje ona wyrażenie i zastępuje. W tym wypadku posłuży nam do małej cenzury tekstów w komórkach.
Składnia:
REGEXREPLACE( tekst ; wyrażenie regularne ; tekst na podmianę )
W tym wypadku tekst na podmianę wpiszemy z palca i powstanie funkcja:
=REGEXREPLACE(B3:B11;$J$3;"!@#$%&")
Jej zadaniem jest wstawienie !@#$%& w miejsce każdego ze “słów zakazanych” spisanych w komórce J3.
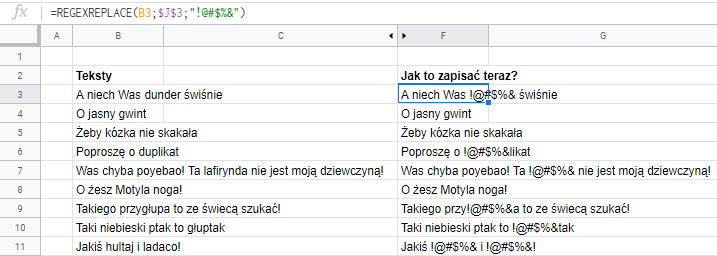
Jak się przyjrzycie, to zauważycie że o ile funkcja REGEXEXTRACT dawała nam tylko pierwsze wystąpienie poszukiwanej frazy, tak REGEXREPLACE wymienia wszystkie (w linii 11 występują 2 frazy – “hultaj” i “ladaco”).
Zastosowanie tej metody w pracy, czyli wykrywamy producenta w długiej nazwie
Powyższe zastosowanie może się wydać czysto rozrywkowe i nieprzydatne w biznesie, komercji, czy innych sprawach, które załatwia się między hektolitrami kawy i filmami na youtube.
Swego czasu miałem problem – z długiej listy produktów w sklepach internetowych musiałem wydobyć nazwy producentów. Wiedziałem, że jest to ograniczona lista firm, ale te nazwy nie miały swojego stałego miejsca w nazwie produktu. Czasem był to pierwszy wyraz, czasem czwarty, etc. A potrzebowałem wyfiltrować produkty tylko jednej firmy.
Zobaczmy roboczy przykład:
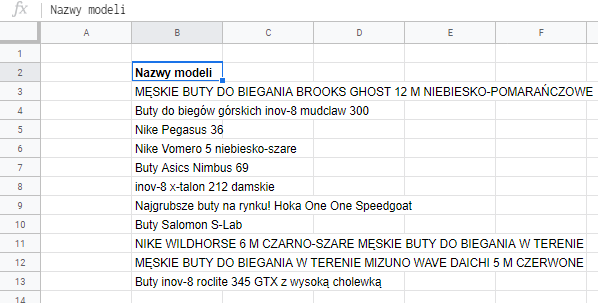
Idąc śladem z poprzedniego przykładu, robię tabelę producentów których mogę się spodziewać, a następnie sklejam ją w jedną komórkę z której będzie pobierana:
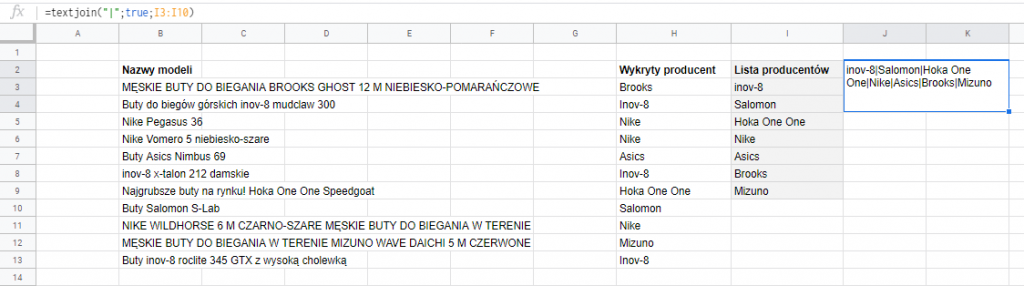
Mam listę, ale widzę że jest bałagan w wielkościach liter. Mogę uporządkować dane źródłowe, ale ciekawiej będzie jeśli sprawię, że formuła REGEXEXTRACT wydobywająca dane stanie się niewrażliwa na wielkość liter i uporządkuje nazwy producentów już po wydobyciu.
Zróbmy to! (jak brzmi slogan jednej z tych firm)
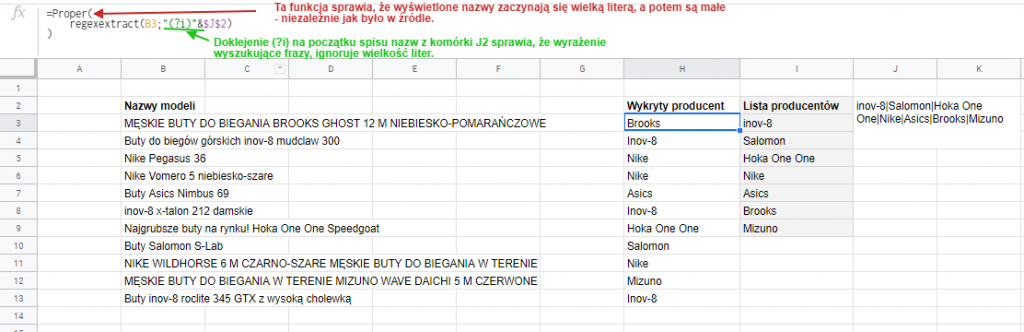
Żeby uzyskać dobrą wyszukiwarkę, sprawiamy by była niewrażliwa na wielkość liter. Służy do tego znacznik (?i) wstawiany na początku wyrażenia regularnego (to jeden z długiej listy znaczników – całość możecie znaleźć tutaj. Zrobił się z tego nieco zagmatwany ciąg:
regexextract(B3;"(?i)"&$J$2) to to samo co:
regexextract(B3;"(?i)inov-8|Salomon|Hoka One One|Nike|Asics|Brooks|Mizuno")
Dlatego, że biorę najpierw ciąg znaków w cudzysłowie, a potem przy pomocy & przyklejam do niego zawartość komórki J2. Sposoby łączenia ciągów opisałem już wcześniej.
W ten sposób uzyskaliśmy nazwy produktów z wydzielonymi producentami:

I teraz, jeśli chcemy – możemy się zająć filtrowaniem i sortowaniem. Ale o tym jest osobny wpis.
 Czym są wyrażenia regularne i dlaczego powinieneś je znać?
Czym są wyrażenia regularne i dlaczego powinieneś je znać? Jak zamienić DUŻE LITERY na małe, odwrotnie i jak zaczynać z wielkiej litery
Jak zamienić DUŻE LITERY na małe, odwrotnie i jak zaczynać z wielkiej litery Jak oczyścić zdobyte dane. Jak zmienić format na liczbowy, usunąć nazwy walut i inne śmieci.
Jak oczyścić zdobyte dane. Jak zmienić format na liczbowy, usunąć nazwy walut i inne śmieci. Jak nauczyć arkusz czytać sumy. Na przykład taki zapis: 3,20 zł za piwo + 0,50 zł butelka.
Jak nauczyć arkusz czytać sumy. Na przykład taki zapis: 3,20 zł za piwo + 0,50 zł butelka.